Zero to Live in a Week: What That Actually Requires
Composable AI architecture, methodical planning, and the twenty-year-old principle that makes it all possible
Part 3 of The Accidental Agentic Enterprise series. [Start with Part 1 here.]
Author: John Pettifor
OK — now we’re talking about the technology.
Part 1 told the origin story. Part 2 was about the humans. This is the post people have been waiting for: how do you actually go from nothing to a working agent in production in a week? And more importantly, what makes that possible. Because the answer isn’t “move fast and break things”. The answer is the opposite.
The week is real: we’ve done it. But the week only works because of the months of deliberate architectural decisions that came before it. If you skip that part, you don’t get speed — you get a demo that falls apart the moment it touches real data.
Here’s what we actually built, why we built it that way, and the principle underneath all of it that’s been true for twenty years.
The Principle behind AI Architecture: Composable, Connectable, Replaceable
If you’ve spent any time in enterprise integration, you’ve heard some version of this before. Good ETL architecture has always followed the same principle: separate your extraction from your transformation from your loading. Keep your layers clean. Make every component independently deployable. Design for the swap, not just the build.
That principle only became more important when AI showed up.
The AI landscape right now is a Cambrian explosion of tools, models, protocols, and platforms — all evolving at a pace that makes last year’s best practice look quaint. New LLMs are dropping quarterly. New agent frameworks appear monthly. The model you build on today might not be the model you want to run on in six months. The MCP server you’re using might get replaced by something better. The interface your team uses today might not be the interface they use next year, and you can’t predict which direction that moves.
If your architecture can’t absorb those changes without a rebuild, you don’t have an architecture. You have a prototype with a deadline.
The organizations that will move fastest with AI aren’t the ones chasing the newest model or the hottest framework. They’re the ones who build a composable foundation where every layer — the interface, the orchestration, the reasoning, the data — can evolve independently. Snap in. Snap out. No rewiring the whole system because one piece changed.
This is the same principle that made good middleware, API design, and data architecture valuable. AI simply raised the stakes on the set of rules we already had.
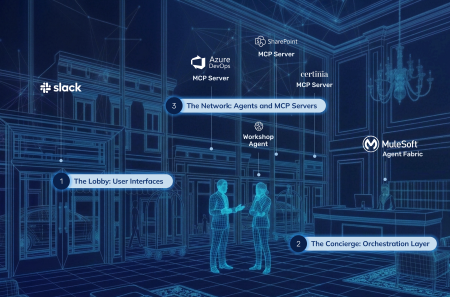
The Architecture: The Lobby, The Concierge, and The Network
We needed a mental model that our whole team could understand — not just the engineers, but the delivery leads, the solution architects, everyone who would eventually interact with these agents. So we thought about AI orchestration like a hotel.
When you walk into a great hotel, you don’t need to know which restaurant has availability tonight, which car service covers your destination, or which tour operator is right for your group. You walk up to the concierge, tell them what you need, and the right thing happens. The concierge knows the network, knows the house rules, knows your preferences, and routes your request to the right provider with the right context. You get the outcome without managing the complexity.
That’s the 3-layer architecture we built for Delivery Intelligence™.
The Lobby: User Interfaces
This is where people walk in and express intent. Slack is our primary interface: it’s where our team initiates conversations with agents, asks questions, and kicks off workflows. But not everything belongs in a chat window. When an agent generates a full set of requirements with traceability matrices, or produces a structured solution design, you want to review that in a proper application UI — something purpose-built for navigating large, structured data sets. So the Lobby isn’t one door. It’s conversational interfaces like Slack for interaction, and traditional application UIs for consuming the structured output that agents produce.
The critical design decision: the Lobby is just a surface. It captures intent and presents responses. It doesn’t contain any intelligence, any routing logic, or any data access. We don’t know what the preferred interfaces will be two years from now — and with this architecture, we don’t need to.
The Concierge: MuleSoft Agent Fabric
This is the orchestration layer. A single broker that receives requests from whatever Lobby is active, classifies intent, and routes that request to the right agent or the right data source with the right context. The Concierge is the reason we can add a new agent without touching any existing agent. It’s the reason we can add a new data source without rewriting any agent logic. It’s the reason we can change the model doing the reasoning without affecting anything above or below it.
Just like a hotel concierge doesn’t just blindly route requests — they know the house rules, they know which guests have access to which services, they don’t send someone somewhere unauthorized — our orchestration layer provides governance natively. PII detection, access control, rate limiting, compliance. It’s built into how every request gets handled.
And it’s the layer most organizations skip. That’s why their first agent works fine, but scaling to a second, third, and fourth becomes exponentially harder as interconnectivity and data dependencies compound. Without a concierge, every guest is on their own making phone calls to providers who don’t know them, don’t know each other, and have no shared rules. That’s what an agent ecosystem looks like without orchestration.
The Network: Agents and MCP Servers
This is where the actual work happens, and it splits into two types. Agents handle reasoning — taking structured input and producing intelligent output. Our Workshop Planning Agent, for example, takes discovery session inputs and generates structured workshop plans. MCP Servers handle data — they expose business systems (Certinia PSA, Azure DevOps, our DKI knowledge base, SharePoint documents) to the ecosystem in a standardized way. Any agent can talk to any MCP server through the Concierge without knowing or caring how that data source is implemented underneath.
The beauty of this model is that every layer scales independently. Need a new way for people to interact with the system? Add a new Lobby. Need a new capability? Build an agent and register it with the Concierge. Need a new data source? Stand up an MCP server. A new restaurant opens across the street? The concierge adds it to the network. None of those changes require touching the other layers.
The Concierge’s “AI Orchestration” Is the Piece Most People Underestimate
Let’s go back to the Concierge for a minute, because it’s the layer that separates a production-grade agentic system from a science project.
When most people think about building AI agents, they think about the model — which LLM, how to prompt it, what to fine-tune. That’s the Network, and it matters. But the Network is also the most replaceable part of the stack. Models get better, cheaper, and faster every quarter. The agent you build today on GPT-4o might run better on Claude next quarter and on something that doesn’t exist yet the quarter after that. Service providers come and go. The concierge endures.
The orchestration layer is what makes all of that flexibility possible. MuleSoft Agent Fabric gives us several things that would take months to build from scratch and would be a nightmare to maintain ourselves.
-
A single broker that routes intent to capability
When a solution architect types a request in Slack, they don’t need to know which agent handles it, which model powers it, or which data sources it needs. The Concierge figures that out. That’s not a convenience feature —it’s the difference between a system that scales and one that requires users to memorize which bot does what. A guest in a great hotel doesn’t need the phone numbers of every restaurant in the city. They just tell the concierge what they’re in the mood for.
-
Governance out of the box
Flex Gateway provides PII detection, attribute-based access control, rate limiting, and spike control — all natively, without writing custom middleware. When you’re building agents that touch project data, financial data, and client-specific documentation, governance isn’t optional. It’s the thing that determines whether your CISO lets you go to production. A great concierge doesn’t just route requests — they know the house rules and enforce them invisibly.
-
Agent discovery and standard protocols
This is the part that directly enables the “one week” claim. MCP plus Google’s A2A protocol means our agents communicate using industry standards, not proprietary formats. When we build a new agent, we register it with the Concierge, define its capabilities, and it’s discoverable by the entire ecosystem. No custom integration. No bespoke handshake between every pair of agents. A new provider joins the network, the concierge learns about them, and they’re available to every guest immediately.
-
A model-agnostic design
The Concierge doesn’t care if the agent behind a capability is running on Azure AI Foundry, on Salesforce‘s Einstein, on Anthropic‘s Claude, or on something we haven’t tried yet. We’ve run GPT-4o through an A2A adapter and Claude through direct API calls in the same ecosystem. If a model degrades or a provider changes pricing, we swap it at the Network layer. The Concierge doesn’t even notice.
This is the ETL principle in action. The orchestration layer sits between the raw input (user intent, data requests) and the output (agent reasoning, structured responses), and it governs everything that passes through. Just like a well-designed ETL pipeline lets you change your source systems or your target warehouse without rewriting the middle, a well-designed orchestration layer lets you change your interfaces, your models, and your data sources without rewriting your agent ecosystem.
The Planning: Making the One-Week Agent Deployment Possible
Here’s the part that doesn’t fit on a slide but made everything else work.
Before we wrote a single line of code for Delivery Intelligence, we mapped our entire delivery process. Not just the part we wanted to automate first. The whole thing — from initial customer inquiry through solution design, scoping, staffing, build, project management, deployment, and ongoing optimization.
We did this in Lucidchart.
- Detailed process flows for every stage of delivery.
- Every handoff.
- Every decision point.
- Every document that gets produced.
- Every system that gets touched.
And then we asked a different question than most organizations ask. Most teams look at their process and say: “Where can we put an AI agent?” We looked at our process and said: “Where does human judgment actually matter, and where is someone spending hours on work that a well-instructed system could do in minutes — if it had the right context?”
That distinction shaped everything. It’s why our first agent wasn’t a chatbot or a summarizer. It was a Workshop Planning Agent — because workshop planning was the first meaningful place where we could move the needle and meet the needs of the business. Our solution architects were spending hours assembling structured workshop plans that followed well-established patterns. The judgment was in knowing which patterns to apply and how to adapt them to the client. The assembly was just time. That’s the kind of work a well-instructed agent with the right context can do in minutes.
The process-level mapping then fed a second layer of design work that we’ve since formalized into a repeatable pattern. For each agent, before build begins, we produce two things:
- Conversational flow diagrams in Lucidchart: Mapping exactly how the agent interacts with users and systems at each stage
- An Agent Charter: A document that defines the agent’s identity, its pipeline stages, its expected inputs and outputs, and its boundaries, all written in business language.
Agent Charters and Conversational Flow Design
The Agent Charter is the most underrated artifact in our entire AI build process. It forces clarity before complexity, making sure you answer the hard questions before build starts.
- What does this agent do?
- What does it explicitly not do?
- What data does it need at each stage?
- What does good output look like?
- What does bad output look like?
- Who reviews the output?
- Where does it go next in the workflow?
If you can’t answer those questions in plain English, you aren’t ready to build — and no amount of prompt engineering will compensate for that ambiguity.
From Process Map to MCP Server Build List
The planning also forced us to think about data dependencies before we built anything. When the Workshop Planning Agent generates a workshop plan, what does it need to know? It needs:
- our DKI best practices for how we run discovery sessions
- Certinia project history for similar engagements
- the client’s requirements in structured form
- knowledge of what Salesforce products are in scope
That data dependency map became our MCP server build list. We didn’t build MCP servers because someone said “we need data connectors.” We built them because the process map told us exactly which data each agent would need, and MCP servers were the cleanest way to expose it without building point-to-point integrations.
 By the time we sat down to build the first agent, we already knew what it would do, what data it would need, where that data lived, how it would get to the agent, what the output would look like, who would review it, and how it would fit into the broader delivery workflow.
By the time we sat down to build the first agent, we already knew what it would do, what data it would need, where that data lived, how it would get to the agent, what the output would look like, who would review it, and how it would fit into the broader delivery workflow.
Building the Agentic Foundation: The First Sprint
Let’s be specific about what the infrastructure build looked like, because this is the investment that makes everything after it fast.
The POC sprint ran February 10–28, 2025. Three weeks. The output wasn’t an agent — it was a platform.
- MuleSoft Agent Fabric Broker, version 1.3.0, running on CloudHub 2.0 Sandbox — or the Concierge routing everything;
- Certinia PSA MCP Server, version 1.2.3— our project and resource data, exposed through a standard protocol;
- Azure DevOps MCP Server, version 1.0.7 — our work items, code, and sprint data;
- DKI MCP Server, version 1.4.1 —twenty years of proprietary delivery knowledge, searchable via Graph API;
- A Slack adapter in Python via Socket Mode;
- Nine architectural views and eight Architecture Decision Records documenting every choice and why;
- And yes, one agent — the Workshop Planning Agent, running on GPT-4o through an A2Aadapter — to prove the whole thing worked end to end.
On February 26th, a solution architect typed a request in Slack, the broker classified the intent, routed it to the agent, the agent pulled context from Certinia, ADO, and DKI, and generated a structured workshop plan. In seconds.
But here’s the honest part: that first sprint was three weeks, not one. The agent itself took days. The platform underneath it — the broker, the MCP servers, the adapter plumbing, the security model, the architecture documentation — that took the other two and a half weeks.
That was the investment. Here’s the return.
The Payoff: Our Requirements Agent — From Design to Live in Seven Business Days
When we built the Requirements Agent — the next agent after the Workshop Planner —something fundamentally different happened. The timeline compressed from weeks to days. Not because we cut corners, but because the corners had already been built.
The process started with design, not code. Before anyone opened an IDE, we mapped the agent’s conversational flow in Lucidchart diagrams and wrote an Agent Charter. This meant the development team had a precise specification to build against rather than iterating toward a vague outcome.
This is a pattern we now follow for every agent.
From those design inputs, the agent script was generated using AI-assisted scripting —producing a structured Agentforce Agent Script that was configured and activated in sandbox the same day. AI building AI, guided by a precise human-authored specification.
This is where the infrastructure investment paid off. The MuleSoft Agent Fabric Broker, the MCP tool layer, and the ProjectIQ data store had already been built and validated for the Workshop Agent. Wiring the Requirements Agent into that infrastructure was an integration exercise, not a platform build. The broker handles document retrieval, context injection, and tool orchestration autonomously — the reasoning agent focuses exclusively on what it’s good at: extraction, generation, and structured output.
Validation happened through rapid iteration cycles — first in the Salesforce UI with manual inputs, then in the live Slack environment with real project data via ProjectIQ. Output quality was scored systematically at every pipeline stage. Failure modes were documented. Prompt fixes were published between test sessions. We treated agent outputs like software releases with explicit quality criteria — because that’s what they are.
The result: a fully brokered, ProjectIQ-grounded requirements pipeline — capable of extracting requirements from SOWs and transcripts, generating Epics, Features, and Product Backlog Items with full traceability, and producing a Requirements Traceability Matrix — live in a Slack delivery environment in seven business days.
Seven days, and no one heroically pulled all-nighters writing code. The infrastructure was already there, the design was already done before build started, and the architecture meant plugging in a new agent was an integration exercise rather than a rebuild.
What “Live AI Agents” Means
We should be honest about this too, because the word “live” does a lot of heavy lifting in AI marketing.
When we say an agent is live, we mean it’s in production on real projects, generating real outputs that real people use in their real delivery work. We don’t mean it’s finished, or that it operates without human review.
“Live” means useful. Not perfect.
Our Workshop Planning Agent generates structured workshop plans that previously required hours of senior consultant time to assemble manually. The Requirements Agent extracts requirements from SOWs and transcripts and produces full traceability matrices. In both cases, a human still reviews and refines every output — because the agent handles the structured assembly and the human handles the judgment. The combination is faster, more consistent, and more thorough than either one working alone.
And because the architecture is composable, we improve continuously without disrupting what’s already working. Every two weeks, we ship a release that adds meaningful capability — a new document type, better reasoning for a specific scenario, a new data source connected through a new MCP server. Each release is a snap-in, not a rewrite.
That’s what composable architecture buys you. Speed isn’t a one-time event. Speed is a sustained capability — the ability to keep improving, keep adding, keep shipping without breaking what you’ve already built.
The Lesson: Architecture Is the Multiplier
The speed at which you can build and deploy AI agents is a function of the architecture underneath them, not the model powering them.
A brilliant model on a bad architecture produces a demo. A good model on a composable architecture produces a production system that gets better every two weeks.
The same principles that have governed good integration design for twenty years — separate your layers, design for the swap, govern the middle, keep your components independently deployable — are exactly the principles that make agentic AI work at enterprise scale.
And the results speak for themselves: a three-week infrastructure investment that produced a production-ready orchestration layer, four MCP servers, and a working agent — followed by a seven-day build cycle for the next agent that plugged into the same platform without touching a single piece of existing infrastructure. That’s not a one-time trick. That’s a repeatable pattern, and it’s how we’re scaling from one agent to a full delivery intelligence suite — with thirteen more agents planned across five business domains.
The week is real. But the thinking that makes the week possible is the real competitive advantage.
Where We Are Now
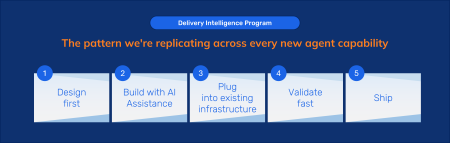
Delivery Intelligence is live and shipping biweekly releases. TheWorkshop Planning Agent and Requirements Agent are in production on active projects.We’re adding meaningful capability with every release cycle, and each new agent follows thesame pattern: design first, build with AI assistance, plug into existing infrastructure, validatefast. Next post in the series digs into why Salesforce’s “boring” structured platform is thefoundation that makes all of this trustworthy at scale.
Diabsolut is a Salesforce consulting partner building the agentic enterprise in the open. Follow the series to see what’s working, what we’re learning, and what’s coming next.
Want to see Delivery Intelligence in action?
Read more in our Agentic Enterprise Series
- Part 1: Diabsolut: The Accidental Agentic Enterprise
- Part 2: Agents Don’t Run the Show — People Do
- Part 3: Zero to Live in a Week: What That Requires
- Part 4: Building on Salesforce’s Boring Foundation (We Mean That as a Compliment)
- Part 5: Why We Don’t Build Everything Ourselves
- Part 6: The Right Answer for Right Now