Solution déployée en une semaine : c’est maintenant possible, et voici comment
Une architecture d’IA modulaire, une planification méthodique, et le principe éprouvé depuis vingt ans qui rend tout cela possible
Partie 3 de la série The Accidental Agentic Enterprise. [Lisez la partie 1 ici.]
Auteur: John Pettifor
Le principe derrière l’architecture IA : modulaire, connectée, remplaçable
Si vous avez déjà travaillé sur l’intégration en entreprise, vous avez probablement entendu une version de ce principe. Une bonne architecture ETL a toujours suivi la même logique : séparer l’extraction de la transformation et du chargement. Garder des couches bien distinctes. Rendre chaque composant déployable indépendamment. Concevoir pour le remplacement, pas seulement pour la construction.
Ce principe est devenu encore plus essentiel avec l’arrivée de l’IA.
Aujourd’hui, le paysage de l’IA ressemble à une explosion cambrienne d’outils, de modèles, de protocoles et de plateformes — tous évoluant à un rythme tel que les meilleures pratiques d’hier paraissent déjà dépassées. De nouveaux LLM sortent chaque trimestre. De nouveaux frameworks d’agents apparaissent chaque mois. Le modèle que vous utilisez aujourd’hui ne sera peut-être plus celui que vous voudrez utiliser dans six mois. Le serveur MCP que vous utilisez pourrait être remplacé par une meilleure alternative. L’interface utilisée par votre équipe aujourd’hui ne sera peut-être pas celle de demain — et il est impossible de prévoir dans quelle direction cela évoluera.
Si votre architecture ne peut pas absorber ces changements sans nécessiter une refonte complète, ce n’est pas une architecture. C’est un prototype avec une date limite.
Les organisations qui avanceront le plus vite avec l’IA ne sont pas celles qui courent après le dernier modèle ou le framework le plus tendance. Ce sont celles qui construisent une base composable, où chaque couche — l’interface, l’orchestration, le raisonnement, les données — peut évoluer indépendamment. On ajoute, on remplace, sans devoir tout reconfigurer parce qu’un seul élément a changé.
C’est le même principe qui a rendu le middleware, la conception d’API et l’architecture des données si précieux. L’IA n’a fait qu’augmenter les enjeux autour de règles que nous connaissions déjà.
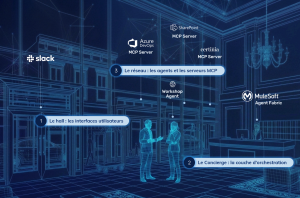
L’architecture : le hall, le concierge et le réseau
Nous avions besoin d’un modèle mental que toute l’équipe puisse comprendre — pas seulement les ingénieurs, mais aussi les responsables delivery, les architectes de solutions, et tous ceux qui interagiront avec ces agents. Nous avons donc pensé l’orchestration de l’IA comme un hôtel.
Quand vous entrez dans un grand hôtel, vous n’avez pas besoin de savoir quel restaurant a de la disponibilité ce soir, quel service de transport couvre votre destination, ou quel prestataire d’excursions convient à votre groupe. Vous vous adressez au concierge, vous expliquez votre besoin, et la bonne solution est mise en place. Le concierge connaît le réseau, les règles de la maison, vos préférences, et oriente votre demande vers le bon prestataire avec le bon contexte. Vous obtenez le résultat sans gérer la complexité.
C’est l’architecture en trois couches que nous avons construite pour Delivery Intelligence™.
Le hall : les interfaces utilisateurs
C’est là que les utilisateurs entrent et expriment leur intention. Slack est notre interface principale : c’est là que notre équipe interagit avec les agents, pose des questions et lance des workflows. Mais tout ne se prête pas à une interface conversationnelle. Lorsqu’un agent génère un ensemble complet d’exigences avec des matrices de traçabilité, ou produit une conception de solution structurée, il est préférable de consulter cela dans une interface applicative dédiée — conçue pour naviguer dans des ensembles de données complexes et structurés. Le hall n’est donc pas une seule porte : il combine des interfaces conversationnelles comme Slack pour l’interaction, et des interfaces applicatives classiques pour exploiter les résultats structurés produits par les agents.
La décision clé : le hall n’est qu’une surface. Il capte l’intention et affiche les réponses. Il ne contient aucune intelligence, aucune logique de routage, ni accès direct aux données. Nous ne savons pas quelles seront les interfaces privilégiées dans deux ans — et avec cette architecture, nous n’avons pas besoin de le savoir.
Le concierge : MuleSoft Agent Fabric
C’est la couche d’orchestration. Un broker central qui reçoit les requêtes depuis n’importe quel point d’entrée (le hall), comprend l’intention et les dirige vers le bon agent ou la bonne source de données avec le bon contexte. Le concierge est la raison pour laquelle nous pouvons ajouter un nouvel agent sans modifier les autres. C’est aussi ce qui nous permet d’intégrer une nouvelle source de données sans réécrire la logique des agents. Et c’est ce qui nous permet de changer le modèle utilisé pour le raisonnement sans impacter le reste du système.
Comme un concierge d’hôtel, il ne se contente pas de transmettre les demandes : il connaît les règles de la maison, sait quels utilisateurs ont accès à quels services, et évite tout accès non autorisé. Notre couche d’orchestration intègre donc nativement la gouvernance : détection des données sensibles (PII), gestion des accès, limitation de débit, conformité… Tout cela est inclus dans le traitement de chaque requête.
Et c’est précisément la couche que la plupart des organisations négligent. C’est pourquoi leur premier agent fonctionne, mais que le passage à un deuxième, troisième ou quatrième devient exponentiellement plus complexe, à mesure que les interconnexions et dépendances de données s’accumulent. Sans concierge, chaque utilisateur doit se débrouiller seul, contacter des services qui ne se connaissent pas, sans règles communes. C’est exactement à quoi ressemble un écosystème d’agents sans orchestration.
Le réseau : les agents et les serveurs MCP
C’est là que le travail réel se fait, et cela se divise en deux types.
Les agents gèrent le raisonnement — ils prennent des données structurées en entrée et produisent des résultats intelligents. Par exemple, notre agent de planification d’ateliers transforme les informations issues des sessions de découverte en plans d’ateliers structurés.
Les serveurs MCP gèrent les données — ils exposent les systèmes métiers (Certinia PSA, Azure DevOps, notre base de connaissances DKI, les documents SharePoint ) à l’écosystème de manière standardisée. N’importe quel agent peut communiquer avec n’importe quel serveur MCP via le Concierge, sans avoir besoin de connaître ni de se soucier de la façon dont la source de données est implémentée en dessous.
La force de ce modèle, c’est que chaque couche évolue indépendamment.
Besoin d’une nouvelle façon d’interagir avec le système ? Ajoutez un nouveau hall.
Besoin d’une nouvelle capacité ? Créez un agent et enregistrez-le auprès du Concierge.
Besoin d’une nouvelle source de données ? Déployez un serveur MCP.
Un nouveau restaurant ouvre dans la rue ? Le concierge l’ajoute au réseau.
Aucun de ces changements ne nécessite de modifier les autres couches.
L’orchestration IA du concierge est l’élément que la plupart des gens sous-estiment
Revenons un instant au Concierge, car c’est cette couche qui distingue un système agentique prêt pour la production d’un simple projet expérimental.
Quand la plupart des gens pensent à la création d’agents IA, ils pensent au modèle — quel LLM utiliser, comment le prompt, quoi affiner. C’est le Réseau, et c’est important. Mais c’est aussi la partie la plus remplaçable de la stack. Les modèles deviennent meilleurs, moins chers et plus rapides chaque trimestre. L’agent que vous construisez aujourd’hui sur GPT-4o pourra mieux fonctionner sur Claude le trimestre prochain, puis sur quelque chose qui n’existe pas encore ensuite. Les fournisseurs changent. Le concierge, lui, reste.
La couche d’orchestration est ce qui rend toute cette flexibilité possible. MuleSoft Agent Fabric nous apporte plusieurs éléments qui prendraient des mois à construire et seraient extrêmement complexes à maintenir en interne.
-
Un broker unique qui relie l’intention à la capacité
Lorsqu’un architecte de solutions saisit une demande dans Slack, il n’a pas besoin de savoir quel agent va la traiter, quel modèle est utilisé, ni quelles sources de données sont nécessaires. Le Concierge s’en charge. Ce n’est pas un simple confort — c’est la différence entre un système scalable et un système où les utilisateurs doivent mémoriser quel bot fait quoi. Dans un bon hôtel, un client n’a pas besoin de connaître les numéros de tous les restaurants : il dit simplement ce qu’il souhaite.
-
Une gouvernance native
Flex Gateway fournit la détection des données sensibles (PII), le contrôle d’accès basé sur les attributs, la limitation de débit et la gestion des pics — le tout sans middleware personnalisé. Quand vos agents accèdent à des données projets, financières ou spécifiques à des clients, la gouvernance n’est pas optionnelle. C’est ce qui détermine si votre CISO vous autorise à passer en production. Un bon concierge ne fait pas que rediriger : il connaît les règles et les applique de manière invisible.
-
Découverte des agents et protocoles standards
C’est ce qui rend concrètement possible la promesse du « une semaine ». MCP, combiné au protocole A2A Google, permet à nos agents de communiquer via des standards industriels plutôt que des formats propriétaires. Lorsqu’un nouvel agent est créé, il est enregistré auprès du Concierge, ses capacités sont définies, et il devient immédiatement accessible à tout l’écosystème. Pas d’intégration spécifique. Pas de connexions sur mesure entre chaque agent. Un nouveau prestataire rejoint le réseau, le concierge l’intègre, et il est instantanément disponible pour tous.
-
Une architecture indépendante des modèles
Le Concierge ne dépend pas du modèle utilisé derrière un agent. Qu’il fonctionne sur Azure AI Foundry, Salesforce Einstein, Claude d’Anthropic, ou toute autre solution, cela ne change rien. Nous avons déjà utilisé GPT-4o via un adaptateur A2A et Claude via des appels API directs dans le même écosystème. Si un modèle devient moins performant ou si un fournisseur modifie ses tarifs, on le remplace au niveau du Réseau. Le Concierge ne s’en aperçoit même pas.
C’est le principe ETL appliqué à l’IA. La couche d’orchestration se situe entre l’entrée (intention utilisateur, requêtes de données) et la sortie (raisonnement des agents, réponses structurées), et elle contrôle tout ce qui transite. Tout comme un pipeline ETL bien conçu permet de changer les systèmes sources ou la destination sans réécrire le cœur du système, une orchestration bien pensée permet de faire évoluer interfaces, modèles et sources de données sans reconstruire tout l’écosystème d’agents.
La planification : rendre possible le déploiement d’un agent en une semaine
Voici la partie qui ne tient pas sur une slide, mais qui a rendu tout le reste possible.
Avant d’écrire une seule ligne de code pour Delivery Intelligence, nous avons cartographié l’ensemble de notre processus de delivery. Pas seulement la partie que nous voulions automatiser en premier. L’ensemble — depuis la première prise de contact client jusqu’à la conception de solution, le cadrage, le staffing, la construction, la gestion de projet, le déploiement et l’optimisation continue.
Nous avons fait cela dans Lucidchart.
- Des flux de processus détaillés pour chaque étape du delivery.
- Chaque point de passage.
- Chaque point de décision.
- Chaque document produit.
- Chaque système impliqué.
Puis nous avons posé une question différente de celle que la plupart des organisations se posent. La plupart des équipes regardent leur processus et se demandent : « Où peut-on intégrer un agent IA ? »
Nous, nous avons demandé : « Où le jugement humain est-il réellement nécessaire, et où quelqu’un passe-t-il des heures sur un travail qu’un système bien guidé pourrait accomplir en quelques minutes — s’il dispose du bon contexte ? »
Cette distinction a tout changé. C’est pourquoi notre premier agent n’était ni un chatbot ni un outil de résumé. C’était un agent de planification d’ateliers — parce que c’était le premier point à fort impact, capable de répondre à un besoin concret du métier. Nos architectes de solutions passaient des heures à assembler des plans d’ateliers structurés, suivant des modèles bien établis. Le jugement résidait dans le choix des bons modèles et leur adaptation au client. L’assemblage, lui, prenait du temps. C’est précisément le type de tâche qu’un agent bien conçu, avec le bon contexte, peut réaliser en quelques minutes.
Cette cartographie du processus a ensuite alimenté une seconde couche de conception, que nous avons depuis transformée en un modèle reproductible. Pour chaque agent, avant même de commencer le développement, nous produisons deux éléments :
- Des diagrammes de flux conversationnels dans Lucidchart : pour définir précisément comment l’agent interagit avec les utilisateurs et les systèmes à chaque étape
- Une Agent Charter : un document qui définit l’identité de l’agent, ses étapes de traitement, ses entrées et sorties attendues, ainsi que ses limites — le tout rédigé en langage métier
Agent Charters et conception des flux conversationnels
L’Agent Charter est l’artefact le plus sous-estimé de tout notre processus de création d’IA. Il impose de la clarté avant la complexité, en vous obligeant à répondre aux questions essentielles avant même de commencer à construire.
- Que fait cet agent ?
- Que ne fait-il explicitement pas ?
- De quelles données a-t-il besoin à chaque étape ?
- À quoi ressemble un bon résultat ?
- À quoi ressemble un mauvais résultat ?
- Qui valide le résultat ?
- Où va-t-il ensuite dans le workflow ?
Si vous n’êtes pas capable de répondre à ces questions simplement, vous n’êtes pas prêt à construire — et aucun niveau de prompt engineering ne compensera ce manque de clarté.
De la cartographie des processus à la liste des serveurs MCP à construire
Cette phase de planification nous a également obligés à réfléchir aux dépendances de données avant même de développer quoi que ce soit. Lorsque l’agent de planification d’ateliers génère un plan, de quoi a-t-il besoin ?
- De nos bonnes pratiques DKI pour la conduite des sessions de découverte
- De l’historique des projets dans Certinia pour des cas similaires
- Des exigences du client sous forme structurée
- D’une compréhension des produits Salesforce concernés
Cette cartographie des dépendances de données est devenue notre liste de serveurs MCP à construire. Nous ne les avons pas créés parce que quelqu’un a dit « il nous faut des connecteurs de données ». Nous les avons construits parce que la cartographie des processus nous indiquait précisément quelles données chaque agent nécessitait — et les serveurs MCP étaient le moyen le plus propre de les exposer, sans créer d’intégrations point à point.
Au moment où nous avons commencé à développer le premier agent, tout était déjà défini : ce qu’il ferait, les données nécessaires, où ces données se trouvaient, comment elles seraient accessibles, à quoi ressemblerait le résultat, qui le validerait, et comment il s’intégrerait dans l’ensemble du processus de delivery.
Construire la base agentique : le premier sprint
Soyons précis sur ce à quoi ressemblait la construction de l’infrastructure, car c’est cet investissement qui rend tout le reste rapide.
Le sprint POC s’est déroulé du 10 au 28 février 2025. Trois semaines. Le livrable n’était pas un agent — c’était une plateforme.
- MuleSoft Agent Fabric Broker, version 1.3.0, déployé sur CloudHub 2.0 Sandbox — notre Concierge qui orchestre tout
- Serveur MCP Certinia PSA, version 1.2.3 — nos données projets et ressources, exposées via un protocole standard
- Serveur MCP Azure DevOps, version 1.0.7 — nos work items, code et données de sprint
- Serveur MCP DKI, version 1.4.1 — vingt ans de savoir-faire delivery propriétaire, interrogeable via Graph API
- Un adaptateur Slack en Python via Socket Mode
- Neuf vues architecturales et huit Architecture Decision Records documentant chaque choix et sa justification
- Et oui, un agent — l’agent de planification d’ateliers, exécuté sur GPT-4o via un adaptateur A2A — pour valider le fonctionnement de bout en bout
Le 26 février, un architecte de solutions a saisi une demande dans Slack. Le broker a compris l’intention, l’a routée vers l’agent, qui a récupéré le contexte depuis Certinia, Azure DevOps et DKI, puis a généré un plan d’atelier structuré. En quelques secondes.
Mais voici la réalité : ce premier sprint a duré trois semaines, pas une. L’agent en lui-même a pris quelques jours. La plateforme en dessous — le broker, les serveurs MCP, les connecteurs, le modèle de sécurité, la documentation d’architecture — a pris les deux semaines et demie restantes.
C’était l’investissement. Voici maintenant le retour.
Le retour sur investissement : notre agent de gestion des exigences — de la conception au lancement en sept jours ouvrés
Lors de la création du Requirements Agent — l’agent suivant après le Workshop Planner — quelque chose de fondamentalement différent s’est produit. Le délai est passé de plusieurs semaines à quelques jours. Non pas parce que nous avons pris des raccourcis, mais parce que les fondations étaient déjà en place.
Le processus a commencé par la conception, pas par le code. Avant même d’ouvrir un IDE, nous avons cartographié le flux conversationnel de l’agent dans Lucidchart et rédigé une Agent Charter. L’équipe de développement disposait ainsi d’une spécification claire, plutôt que d’itérer vers un résultat flou.
C’est désormais un modèle que nous appliquons à chaque agent.
À partir de ces éléments de conception, le script de l’agent a été généré grâce à un scripting assisté par IA — produisant un Agentforce Agent Script structuré, configuré et activé en sandbox le jour même. De l’IA qui construit de l’IA, guidée par une spécification humaine précise.
C’est là que l’investissement dans l’infrastructure a porté ses fruits. Le MuleSoft Agent Fabric Broker, la couche d’outils MCP et le datastore ProjectIQ avaient déjà été construits et validés pour le premier agent. Intégrer le Requirements Agent dans cette architecture relevait donc d’un exercice d’intégration, et non de construction de plateforme. Le broker gère automatiquement la récupération de documents, l’injection de contexte et l’orchestration des outils — permettant à l’agent de se concentrer uniquement sur sa spécialité : l’extraction, la génération et la production de résultats structurés.
La validation s’est faite par cycles rapides d’itération — d’abord dans l’interface Salesforce avec des entrées manuelles, puis dans l’environnement Slack en conditions réelles avec des données issues de ProjectIQ. La qualité des résultats a été évaluée de manière systématique à chaque étape du pipeline. Les cas d’échec ont été documentés. Les ajustements de prompts ont été appliqués entre chaque session de test. Nous avons traité les résultats des agents comme des livraisons logicielles, avec des critères de qualité explicites — car c’est exactement ce qu’ils sont.
Résultat : un pipeline complet de gestion des exigences, orchestré par le broker et alimenté par ProjectIQ — capable d’extraire des exigences à partir de SOW et de transcripts, de générer des Epics, Features et Product Backlog Items avec traçabilité complète, et de produire une matrice de traçabilité des exigences — déployé dans un environnement Slack en sept jours ouvrés.
Sept jours, sans nuits blanches héroïques à coder. L’infrastructure était déjà en place, la conception était finalisée avant le développement, et l’architecture permettait d’intégrer un nouvel agent comme un simple branchement, plutôt que de tout reconstruire.

Ce que signifie « agents IA en production »
Soyons honnêtes aussi sur ce point, car le mot « live » est souvent surutilisé dans le marketing de l’IA.
Quand nous disons qu’un agent est en production, cela signifie qu’il est utilisé sur de vrais projets, qu’il génère des résultats réels, exploités par de vraies personnes dans leur travail quotidien. Cela ne veut pas dire qu’il est terminé, ni qu’il fonctionne sans validation humaine.
« Live » signifie utile, pas parfait.
Notre agent de planification d’ateliers génère des plans structurés qui demandaient auparavant des heures de travail manuel à des consultants seniors. Le Requirements Agent extrait des exigences à partir de SOW et de transcripts et produit des matrices de traçabilité complètes. Dans les deux cas, un humain relit et affine chaque résultat — car l’agent s’occupe de l’assemblage structuré, et l’humain du jugement. Ensemble, ils sont plus rapides, plus cohérents et plus complets que chacun séparément.
Et grâce à une architecture composable, nous pouvons améliorer en continu sans perturber ce qui fonctionne déjà. Toutes les deux semaines, nous livrons une nouvelle version apportant une valeur réelle — un nouveau type de document, un raisonnement amélioré pour un cas spécifique, une nouvelle source de données connectée via un serveur MCP. Chaque évolution s’intègre comme une pièce supplémentaire, sans nécessiter de refonte.
C’est cela, la valeur d’une architecture composable. La vitesse n’est pas un événement ponctuel. C’est une capacité durable — celle de continuer à améliorer, à ajouter et à livrer, sans casser ce qui existe déjà.
La leçon : l’architecture est le multiplicateur
La vitesse à laquelle vous pouvez concevoir et déployer des agents IA dépend de l’architecture sous-jacente, et non du modèle qui les alimente.
Un modèle brillant sur une mauvaise architecture produit une démo. Un bon modèle sur une architecture composable produit un système en production qui s’améliore toutes les deux semaines.
Les mêmes principes qui régissent une bonne conception d’intégration depuis vingt ans — séparer les couches, concevoir pour le remplacement, gouverner la couche intermédiaire, maintenir des composants déployables indépendamment — sont exactement ceux qui permettent à l’IA agentique de fonctionner à l’échelle de l’entreprise.
Et les résultats parlent d’eux-mêmes : un investissement de trois semaines dans l’infrastructure qui a permis de créer une couche d’orchestration prête pour la production, quatre serveurs MCP et un agent fonctionnel — suivi d’un cycle de développement de sept jours pour le prochain agent, intégré à la même plateforme sans modifier un seul élément existant. Ce n’est pas un exploit ponctuel. C’est un modèle reproductible, et c’est ainsi que nous passons d’un agent à une suite complète de Delivery Intelligence — avec treize autres agents prévus sur cinq domaines métiers.
La semaine est réelle. Mais la réflexion qui la rend possible est le véritable avantage concurrentiel.
Où nous en sommes aujourd’hui
Delivery Intelligence est en production et évolue avec des releases toutes les deux semaines. Le Workshop Planning Agent et le Requirements Agent sont utilisés sur des projets actifs. Nous ajoutons des fonctionnalités à forte valeur à chaque cycle, et chaque nouvel agent suit le même modèle : conception d’abord, développement assisté par l’IA, intégration dans l’infrastructure existante, validation rapide.
Le prochain article de la série expliquera pourquoi la plateforme structurée — parfois jugée « ennuyeuse » — de Salesforce est en réalité la base qui rend tout cela fiable à grande échelle.
Diabsolut est un partenaire de conseil Salesforce qui construit l’entreprise agentique en toute transparence. Suivez la série pour découvrir ce qui fonctionne, ce que nous apprenons et ce qui arrive ensuite.
Envie de voir Delivery Intelligence en action ?
Prenez rendez-vous avec notre équipe.
En savoir plus dans notre série Agentic Enterprise
- Partie 1 : Diabsolut : The Accidental Agentic Enterprise
- Partie 2 : Les agents ne dirigent pas — ce sont les humains qui le font